Abstract: An often overlooked aspect of working with CUDA is the compilation process, as the effort invested in setting up the environment and utilizing it can be significantly discouraging. This document gathers and organizes available information on NVCC. It also presents solutions provided by NVIDIA for creating custom compilers.
Introduction
Graphics accelerators are one of the fundamental components of ordinary home computers. Their incredible ubiquity is attributed to their utility in processing large data vectors using a single program. The rapidly evolving GPU market has also prompted companies other than NVIDIA to create their own solutions. The combination of dynamic development and strong competition has led to the emergence of a non-standard CUDA program compilation environment.
Currently, the entire process of generating executable code on NVIDIA cards is not fully understood. Only a portion of the NVCC toolchain is documented, yet it still creates an exceptionally rich environment that has undergone significant changes under the influence of projects such as LLVM.
Short history
Originally, NVCC had a strong association with the Open64 compiler 1, whose mutation was utilized to generate intermediate code before compiling it into the specific assembler of the graphics card. Currently, it is challenging to determine the extent to which this has changed, but a different program called CICC is now used for generating IR. This change may have occurred due to the growing importance of the LLVM project in the compiler world.
A significant milestone in the development of CUDA was the proposal of an environment for creating custom CUDA code compilation tools called Compiler SDK. It was developed in the years 2012-2013, as indicated by presentations by, among others, Yuan Lin, a principal engineer at NVIDIA and a member of the team responsible for compilers. These presentations exhibit inconsistencies that may suggest the dynamic process of creation and the crystallization of ideas within the SDK itself. These include the use of the libCUDA.Lang library 2 in presentations - which was never made public, or the revelation of the architecture of one of NVCC’s subprograms in a presentation 3 - which was, however, never confirmed in official documentation. At present, the compiler development environment is stable and linked to the CUDA driver.
Compiler Architecture
Writing programs in CUDA involves using mixed code, containing segments intended for two different units: the processor (host) and the graphics card (device). Two competitive compilation approaches can be distinguished for such a mixture.
Dual-Compilation Mode
The first is the dual-compilation mode, which assumes the creation of only one file with intermediate code. In this scenario, the compiler processes host code in the first pass and device code in the second pass, simultaneously injecting it as a character sequence into the same file. A technology utilizing this approach is the project proposed by Google called gpucc 4, which was intended to be an open-source toolchain for CUDA, using LLVM.
Separated Compilation
The processing sequence used by NVCC involves separated compilation. The idea is to use a splitter, enabling the separation of code executed on the CPU and GPU into distinct files. The actual division is done using special macros: __device__, __global__, which serve as hints for NVCC, as its code is responsible for this step. Subsequently, each file is compiled independently into binary form, so that the device code file can be attached to the host file using #include.
NVCC Toolchain
NVCC is a non-standard compiler, as its operation consists of a series of smaller programs provided by NVIDIA and an external C++ compiler such as g++ or clang. It can be perceived as a toolchain that serves as the infrastructure managing the process of generating binary code for CUDA through proper management of individual programs. Nevertheless, it can be referred to in the category of a compiler.
The exact compilation process has never been fully disclosed. However, in the CUDA Toolkit documentation 5, there is a section that sheds some light on this matter. It is based, in part, on this information that the subsequent part of this work describing NVCC was developed.
The general operation of the considered compiler is depicted in the diagram (Figure 1). The green box highlights the part of the toolchain that compiles a single file with the extension .cu. When a file with a different extension, such as .cpp, is inputted, it is treated as if it does not contain code intended for the GPU. In this case, only the left side of the process intended for CUDA C++ code is executed. The goal of the right side is to generate intermediate and assembly code for the graphics card, and then package it into a collective file for use in host code, for example, during kernel calls. The compilation aspect that is not well-described in any documentation is the inclusion of libraries from the CUDA environment (linking), and therefore, it will be omitted.
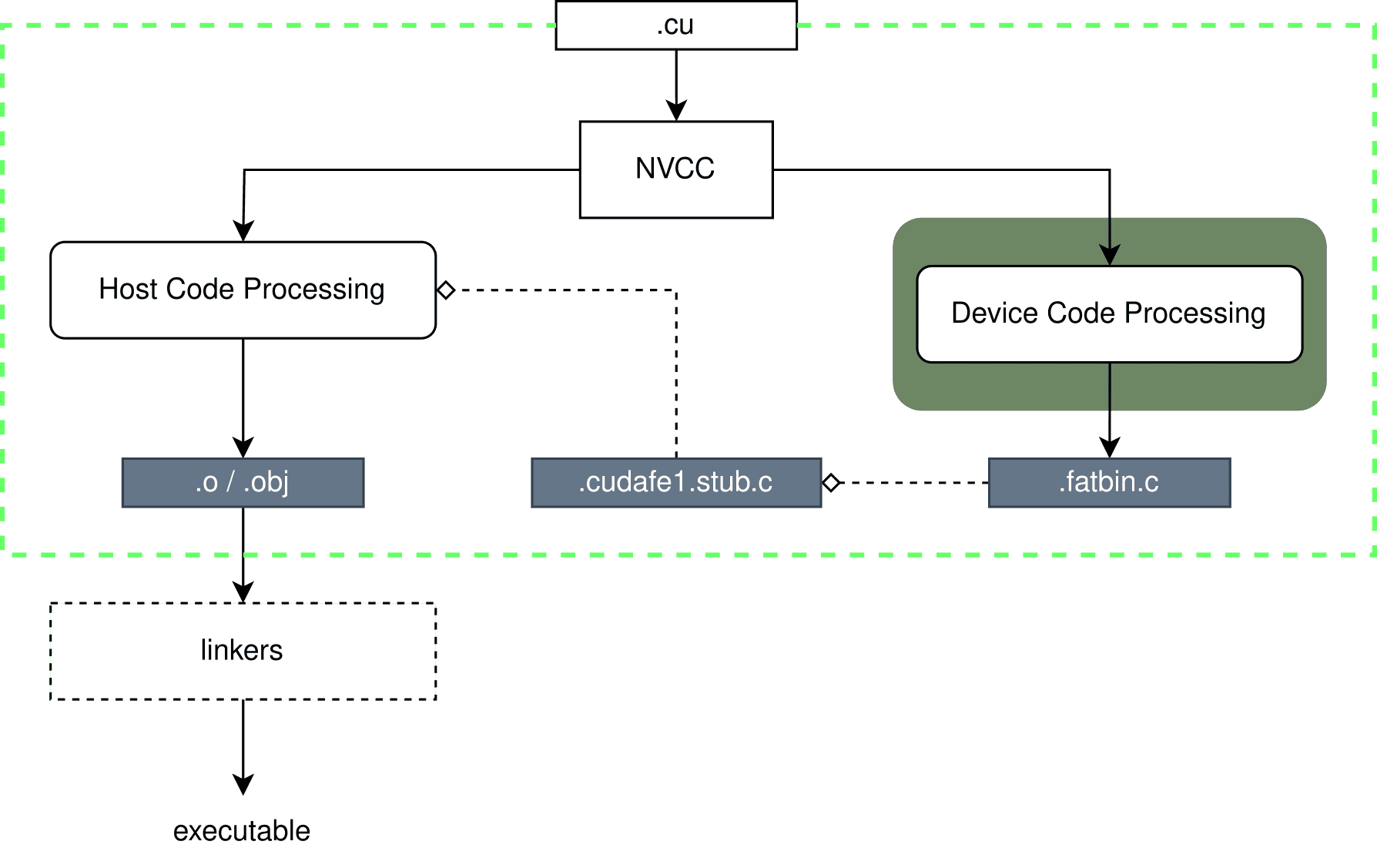
Figure 1. The approach employed by NVCC for compiling mixed CUDA code is separated compilation, which divides the compiler into infrastructure dedicated to host code (left side) and device code (right side).
Processing CUDA C++
At the beginning, we will discuss the sequence that generates binary code executed on the CPU (Figure 2). It consists of three phases and utilizes an external C++ compiler. After separating the processed file, the host code becomes CUDA C++, which is a mutation of the C++ standard, incorporating elements such as kernel calls from the host code. In the first step, all definitions/macros are expanded using the C++ pre-processor, so that the resulting text is directed to cudafe++. This is one of the tools provided by NVIDIA, enabling the transformation of specific CUDA structures into standard C++. The exact translation process is not described anywhere, but it can be assumed that it utilizes functions provided by the CUDA driver. An example of such a structure is <<< … >>>, responsible for kernel invocation, which can be replaced with the cuLaunchKernel(…) driver function.
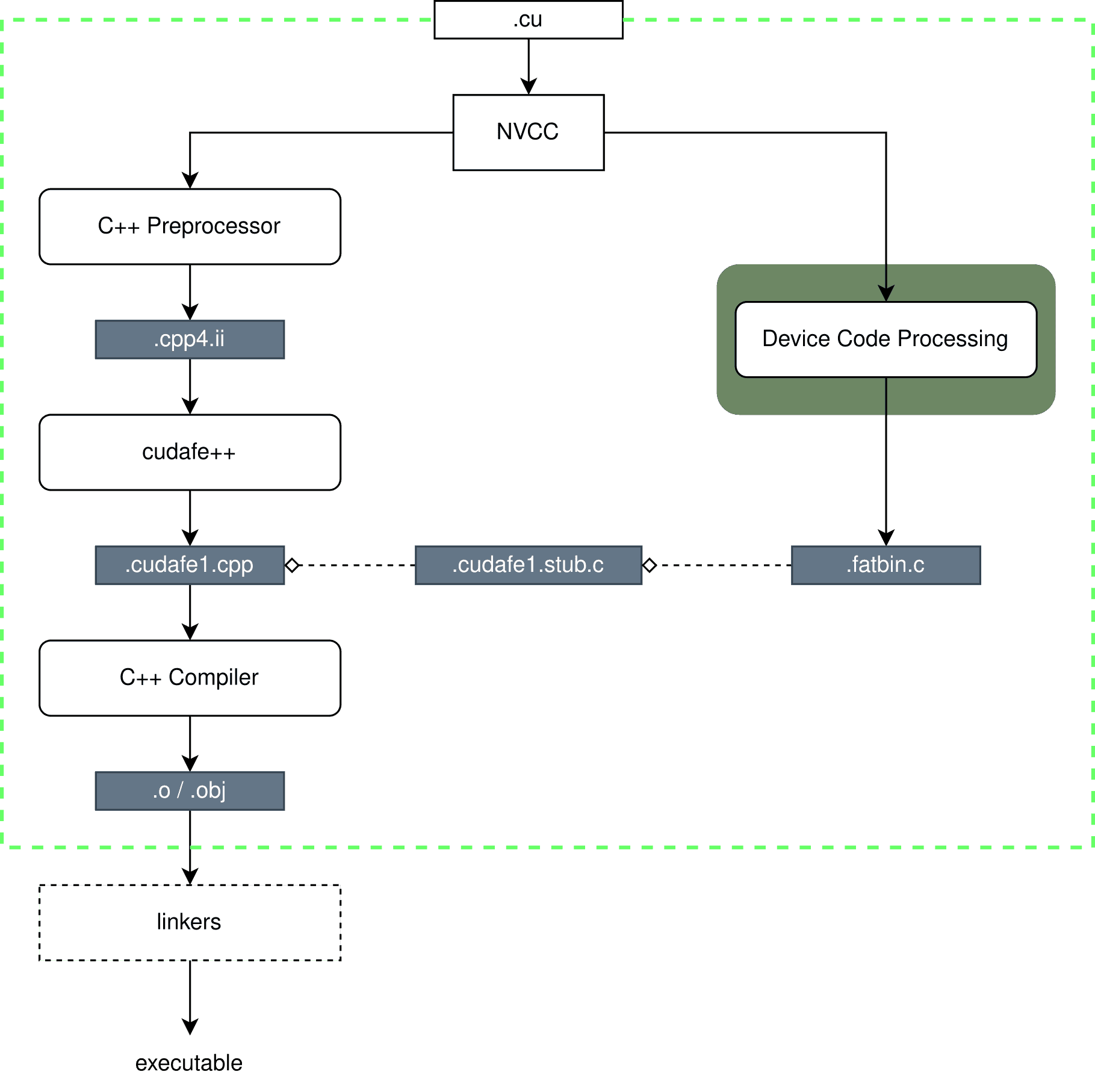
Figure 2. Diagram of host code processing and attachment of the device code file.
The translation process is crucial because NVCC uses an external C++ compiler, so the processed code must ultimately comply with the standard to be compilable. In general, a program created in CUDA is a conglomerate of the binary version of the host code and the textual representation of intermediate (and/or GPU assembly) device code, which is injected into the output file through the inclusion (#include) of the fat binary file. This file is created as a result of processing, including kernels, by the right side of the NVCC toolchain.
Intermediate Representations
Understanding the process of compiling device code requires knowledge of the intermediate representations employed by NVCC. The first intermediate representation is PTX, which simultaneously serves as a model for a virtual graphics card and an assembler (ISA) 6. It allows for the separation of the actual binary code of a GPU program from its theoretical model, providing greater flexibility in terms of hardware instruction implementations for new architectures. PTX always appears in a textual form 5, and its documentation is widely accessible.
NVCC also has the capability to generate SASS as an intermediate representation directly linked to the low-level GPU architecture, and it may differ between individual models. Unfortunately, SASS documentation is not publicly available, and even the expansion of its acronym is unknown. On the internet, you may encounter two versions: Shader ASSembly or Source and ASSembly, and the representation itself is almost never mentioned in official CUDA documents.
Processing Device Code
When considering the processing of device code by NVCC, two key phases can be distinguished. The first one is responsible for generating intermediate forms, marked with a green field in Figure 3. It consists of a C++ preprocessor resolving definitions/macros, which then passes the processed code to cicc. cicc is an external program and part of NVCC responsible for generating PTX and optimizing it. It is possible that this program utilizes functionalities provided by the LLVM project 7, but its earlier version, nvopencc, was strongly linked with the Open64 compiler 1, and certain connections may have been retained. The next step involves passing PTX to ptxas, which produces SASS code in the form of a *.cubin file.
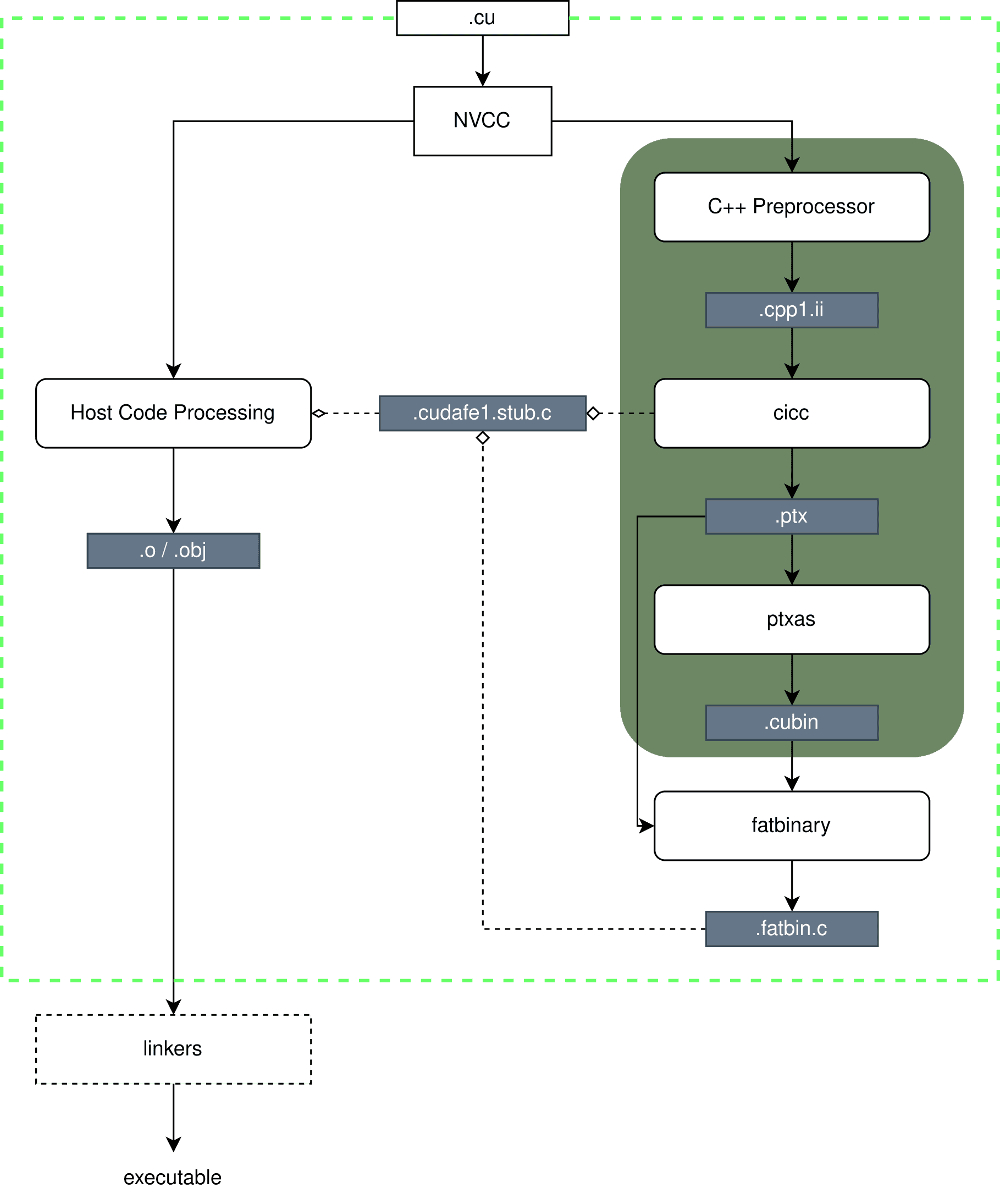
Figure 3. Diagram of device code processing. The green field indicates a part of the toolchain executed for each declared virtual architecture. All architecture codes are archived in a fat binary file.
Due to the fact that the application of CUDA programs often involves intensive computations on multiple graphics cards simultaneously, which is particularly evident in HPC applications, even a few percentage points of computation delay in a cluster can generate significant costs. To mitigate this, NVIDIA introduced the fat binary file. During the first phase of processing device code, additional copies of the code are generated in the form of PTX and optionally SASS for different architectures. In the second phase, all these copies are archived using the fatbinary program into a fat binary file. Its purpose is to provide the most optimal version of device code that the CUDA driver may need for a specific graphics card.
Use of PTX and SASS
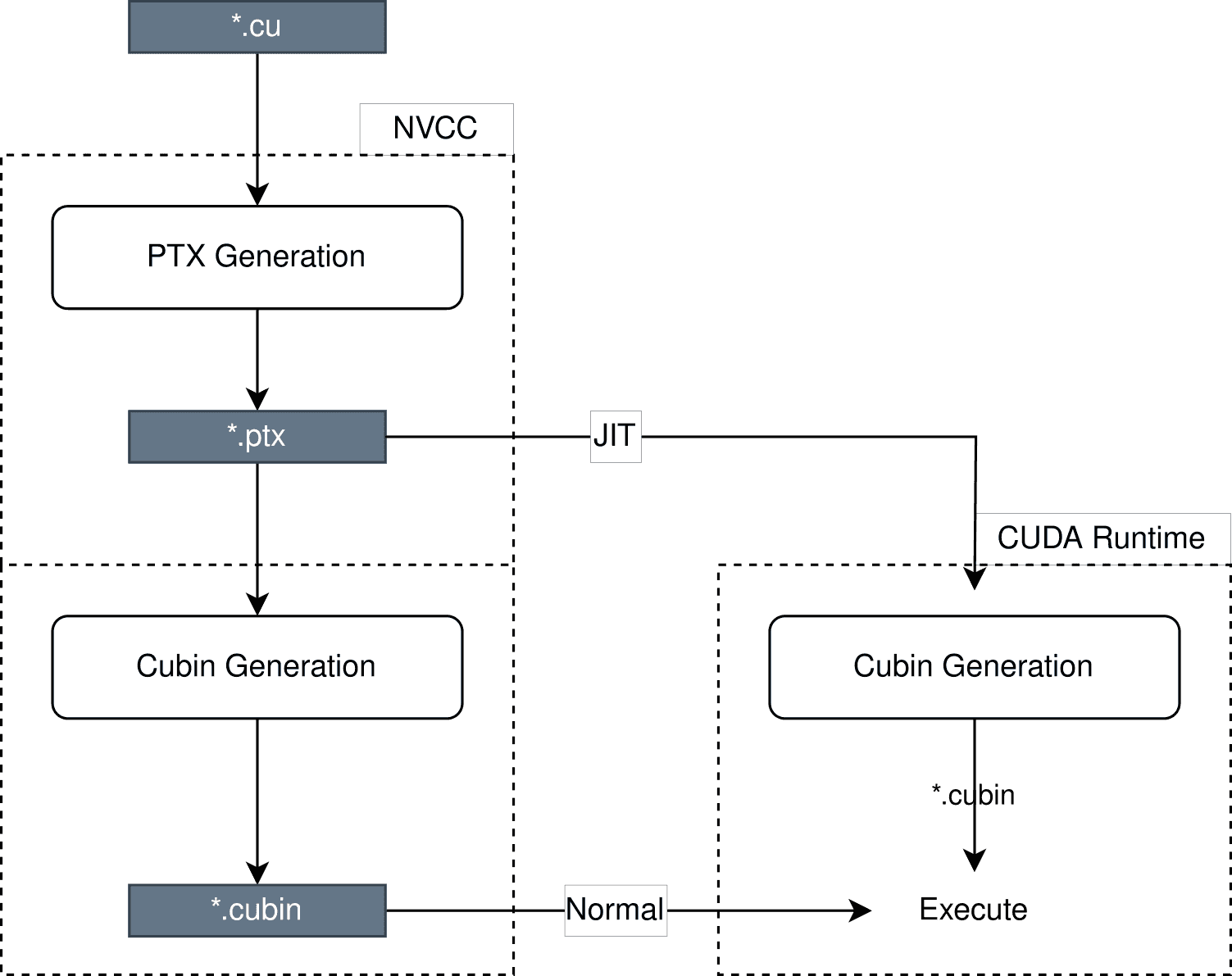
Figure 4. During the execution of a CUDA program, the runtime environment can directly utilize existing SASS code (i.e., *.cubin) included in the fat binary as source code, for example, for a kernel, or use PTX (also from the fat binary) for JIT compilation. This allows the runtime environment, based on the driver’s knowledge, to generate the best binary code (SASS) for the graphics card.
To achieve optimal performance, it is best for the PTX architecture and the resulting SASS to be well-suited for a specific graphics card. The —gpu-architecture option (also known as -arch) and its possible values compute_XY determine the version of PTX and, consequently, the virtual GPU model. Defining the real architecture is handled by the —gpu-code option and values sm_XY. When using NVCC, it is not required to specify a particular GPU architecture for the code. If —gpu-code is omitted, only the PTX for the fat binary will be generated, and the appropriate SASS code will be generated during program execution (Figure 4). This form of compilation is known as just-in-time (JIT) compilation.
In addition to the traditional use of the —gpu-architecture/-arch option, a value of sm_XY can be provided, in case a specific GPU architecture is not explicitly determined using —gpu-code. NVCC will apply the provided value to generate SASS and will find the nearest virtual architecture to generate PTX.
Compiler SDK
For some time now, NVIDIA has been providing an environment beyond NVCC, offering opportunities to create custom compilers. It is worth noting that ‘compiling’ CUDA code essentially boils down to generating normal machine code for the CPU and PTX for device code when using JIT. Therefore, when coupling any language with the GPU, involving kernel interpretation, attention is drawn to issues such as PTX generation and its invocation.
PTX Generation
Currently, PTX can be generated in two ways. The first method involves using the backend provided by LLVM, which, given an acceptable subset of LLVM IR, generates PTX 8. The second method is to utilize NVVM IR, a specific subset of LLVM IR presented by NVIDIA, and the libNVVM API library, which, using functions like nvvmCompileProgram(…), generates PTX code from NVVM IR 9.
PTX Invoking
Invoking PTX code is facilitated by the low-level API of the CUDA driver. One of the functions for this purpose is cuLaunchKernel(…). The use of NVVM IR and the CUDA driver can be seen in one of the examples provided by NVIDIA 10.
Frontend
The biggest challenge is the lack of an open frontend compiler generating LLVM IR or NVVM IR from kernel code. This is a non-trivial problem because the currently available infrastructure for generating LLVM IR cannot be used. This is because both the LLVM backend and the NVIDIA library require a specific subset of LLVM IR, necessitating manual generation of the intermediate representation.
Conclusions
The CUDA compilation environment presents an intriguing solution for mixed-code challenges, and providing access to the documentation of NVVM, libNVVM, and PTX opens up new possibilities. Unfortunately, there are currently numerous obstacles hindering their utilization, mainly associated with the secrecy of certain aspects of NVCC’s implementation by NVIDIA, driven by intense competition in the graphics card market. This is likely motivated by the desire to protect proprietary solutions that contribute to the exceptional efficiency of their brand’s cards. However, it also closes the door to deeper research on the compilation methods of CUDA code.
About the author
Dawid Szpejna is currently employed by Asseco, previously worked at Phoenix System. He is strongly connected in each of his works with artificial language processing, what he learned at the Warsaw University of Technology, studying the program Computer Science and Information Systems at the Faculty of Mathematics and Information Science.
References
-
- Mike Murphy, NVIDIA’s Experience with Open64
-
- Vinod Grover, Yuan Lin, Compiling CUDA and Other Languages for GPUs
-
- Yuan Lin, Building GPU Compilers with libNVVM
-
- Jingyue Wu, Artem Belevich, Eli Bendersky, Mark Heffernan, Chris Leary, Jacques Pienaar, Bjarke Roune, Rob Springer, Xuetian Weng, Robert Hundt, An Open-Source GPGPU Compiler
-
- NVIDIA, NVIDIA CUDA Compiler Driver NVCC
-
- NVIDIA, CUDA LLVM Compiler
-
- LLVM docs, User Guide for NVPTX Back-end
-
- NVIDIA, libNVVVM API
-
- Rob Nertney, 7_libNVVM/simple