The aim of the project is to conduct research and recognize the possibility of using partial evaluation techniques to optimize data processing in processes such as ETL (Extraction Transformation Loading) using parallel algorithms running on GPU. Such optimization can be important from the perspective of data mining or machine learning methods that can be effectively implemented on GPUs. The main focus is on semi-structured data, which is extremely popular in many applications. Their efficient loading and preparation for further processing becomes an important problem both on the scale of individual workstations or entire computing clusters. In order to optimize the ETL process, we need to know the input and output data format, their structure, and the necessary transformations. They can be defined by dedicated languages or be hard-coded in the program. In the former case, the program can be automatically specialized to accept an input that only meets specific assumptions about the format, structure or transformation. For example, usually the input format is defined by a certain grammar, from which a dedicated parser is generated. Having information about the structure and the necessary transformation, it is possible to specialize the program further. In the project we will explore the possibilities of optimizing parallel operations performed while processing data on the GPU through knowledge of the data format, structure and its transformation. These optimizations will be performed before the actual program is compiled using partial execution techniques. Therefore, we assume that there will be a general program available that will be automatically optimized for specific classes of input data. For each necessary data class and transformation it will be possible to perform a new automatic transformation. This will potentially improve performance for all data classes, even if they differ from each other. The automation of ETL-type process optimization will be a significant improvement for the computing industry using GPUs in data processing.
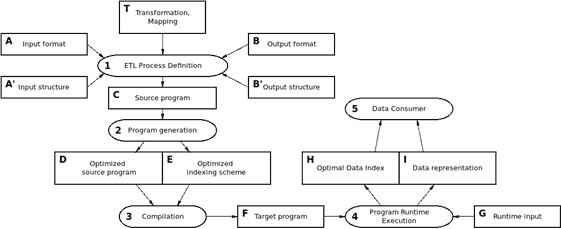 The generated program is enriched with a structure that indexes the data read in an optimal way for a given structure.
The generated program is enriched with a structure that indexes the data read in an optimal way for a given structure.