Abstract: In this short blog post, I show the gains of multiple GPU training, as well as some tips on how to do that efficiently and with minimum additional work.
Introduction
The training time is often a limiting factor in deep learning modelling. In the case of our EdenN cluster, we are limited to a maximum of 5 days of computation. However, as each of the nodes is equipped with 8 GPUs, we can easily scale up and obtain almost 40 days’ worth of computations within those 5 days using all 8 GPUs in single machine. With the introduction of the hopper node (H100), we can even go further and get equivalence of 80 days of A100 work in only 5 days on H100’s.
Multi-GPU scenario
In the case of the Multi-GPU scenario, we can see that adding GPUs significantly reduces the time required for one epoch. Bear in mind that the numbers are just approximations - sometimes, because of external factors, the training can last a bit longer or shorter per GPU; however, the overall rule stands. I have initiated the training of two models on 8 GPUs and 3 GPUs on DGX machines. The time of training is one epoch, which is shown in Figure 1.
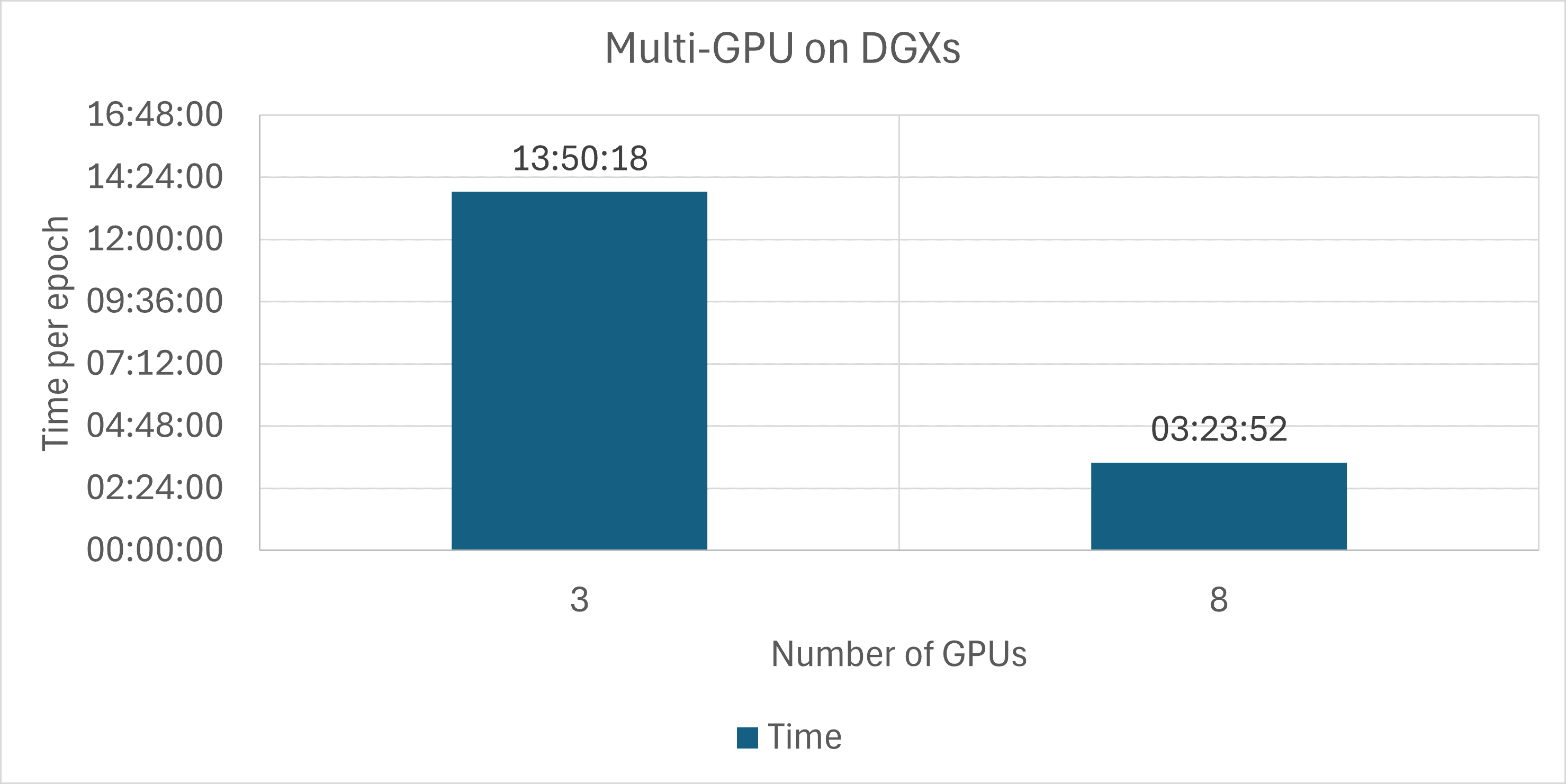
Figure 1. Training time for 3 and 8 GPUS with single Eden node.
To easily train your model using the multi-GPU setting, I suggest using pytorch lightning - a framework that removes most of the boilerplate code and is responsible for managing all the computations. The model can be easily converted from pytorch to pytorch lightning by wrapping them in appropriate modules, and multi-GPU training becomes a matter of just adding more GPUs into the sbatch script. Lightning in default mode will use all the GPUs and the DDP (Distributed Data Parallel) training strategy.
More information can be found in Lightning’s awesome documentation. Trust me, it’s worth spending a couple of hours switching to it.
https://lightning.ai/docs/pytorch/stable/levels/core_skills.html
https://lightning.ai/docs/pytorch/stable/accelerators/gpu_intermediate.html
A100 vs H100
We were promised that H100 GPU would be twice as strong as A100. Using a simple and short test, I verified that it is indeed true. I have trained the same model in the 6-GPU scenario on an Ampere A100 machine and in the 3-GPU Hopper H100 scenario. The entire script (consisting of preprocessing, as well as training 3 epochs) was timed, and the results are shown in Figure 2.
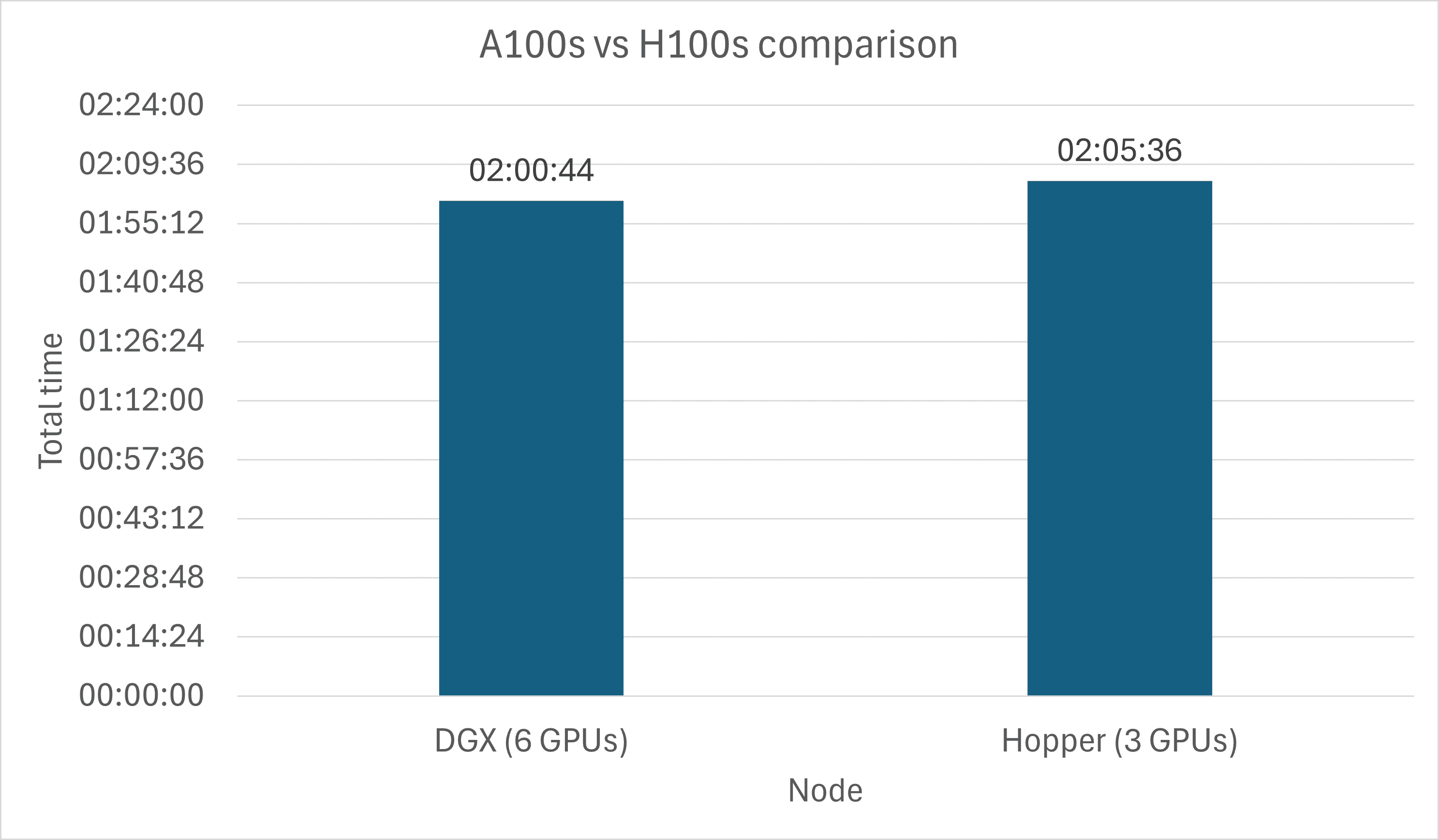
Figure 2. Comparison of 6 x A100 GPU and 3 x H100 GPU training time.
Conclusions
In the case of advanced deep learning modelling, multi-GPU training is often essential to actually train the model in a reasonable time. Our EDEN cluster, along with modern frameworks like pytorch lightning, allows us to easily scale up the training - and obtain the results much, much faster.